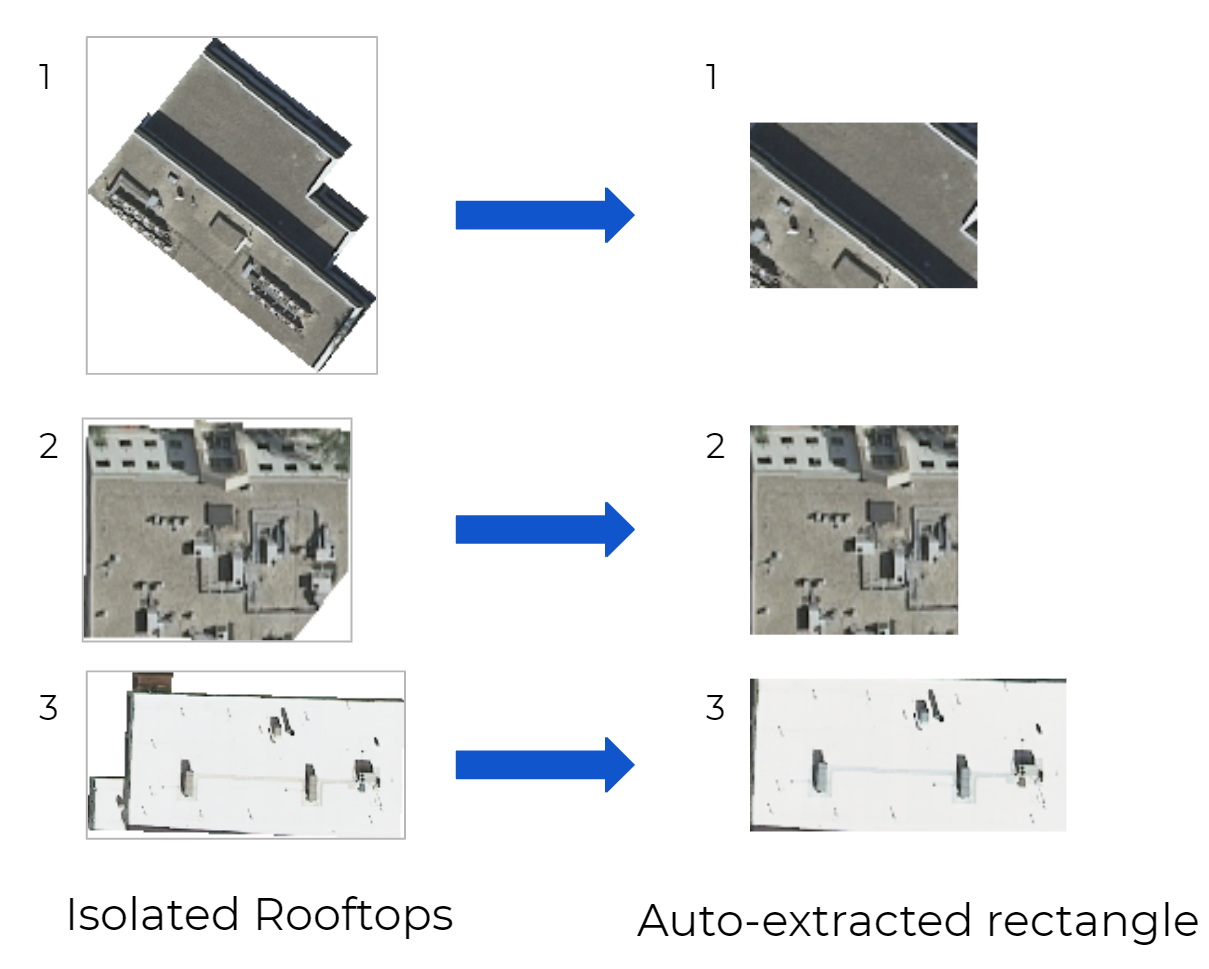
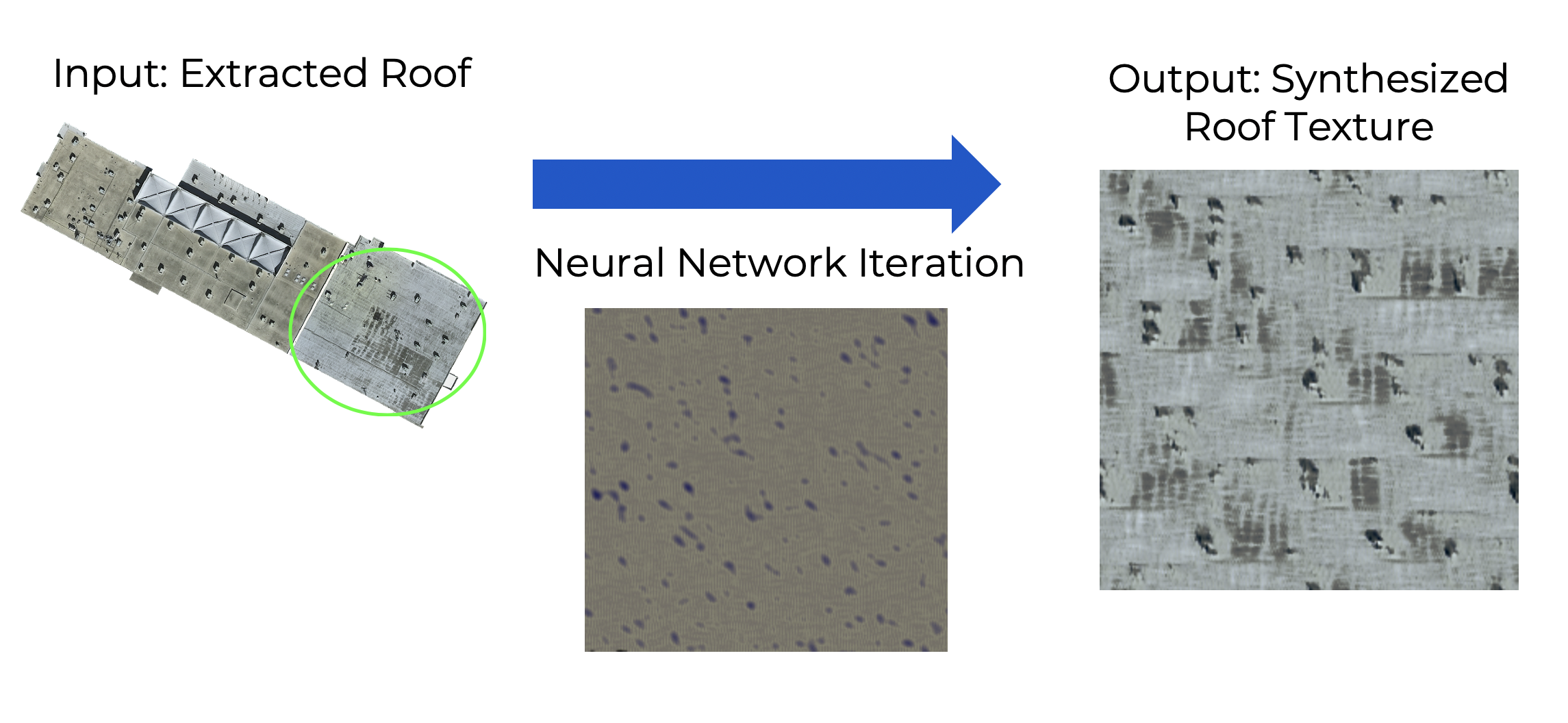
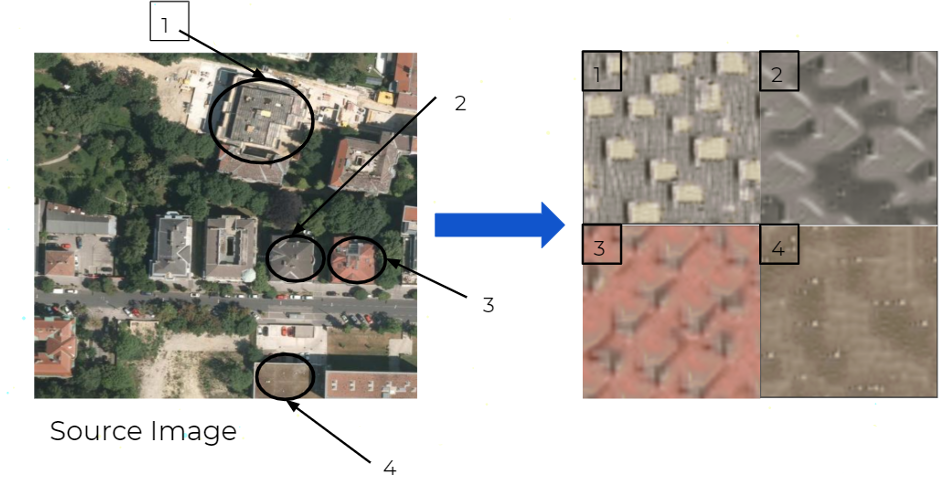
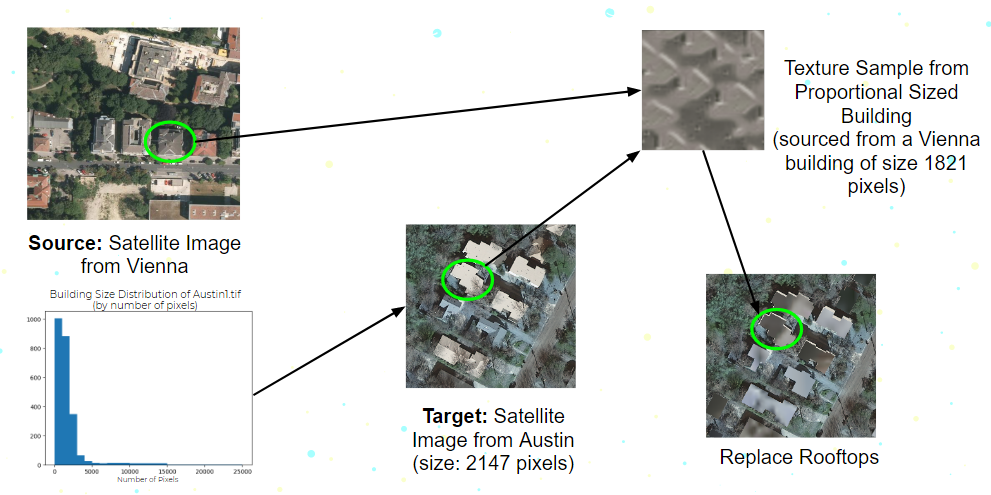
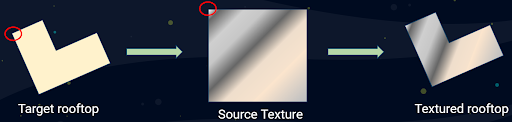
Introduction
Motivation
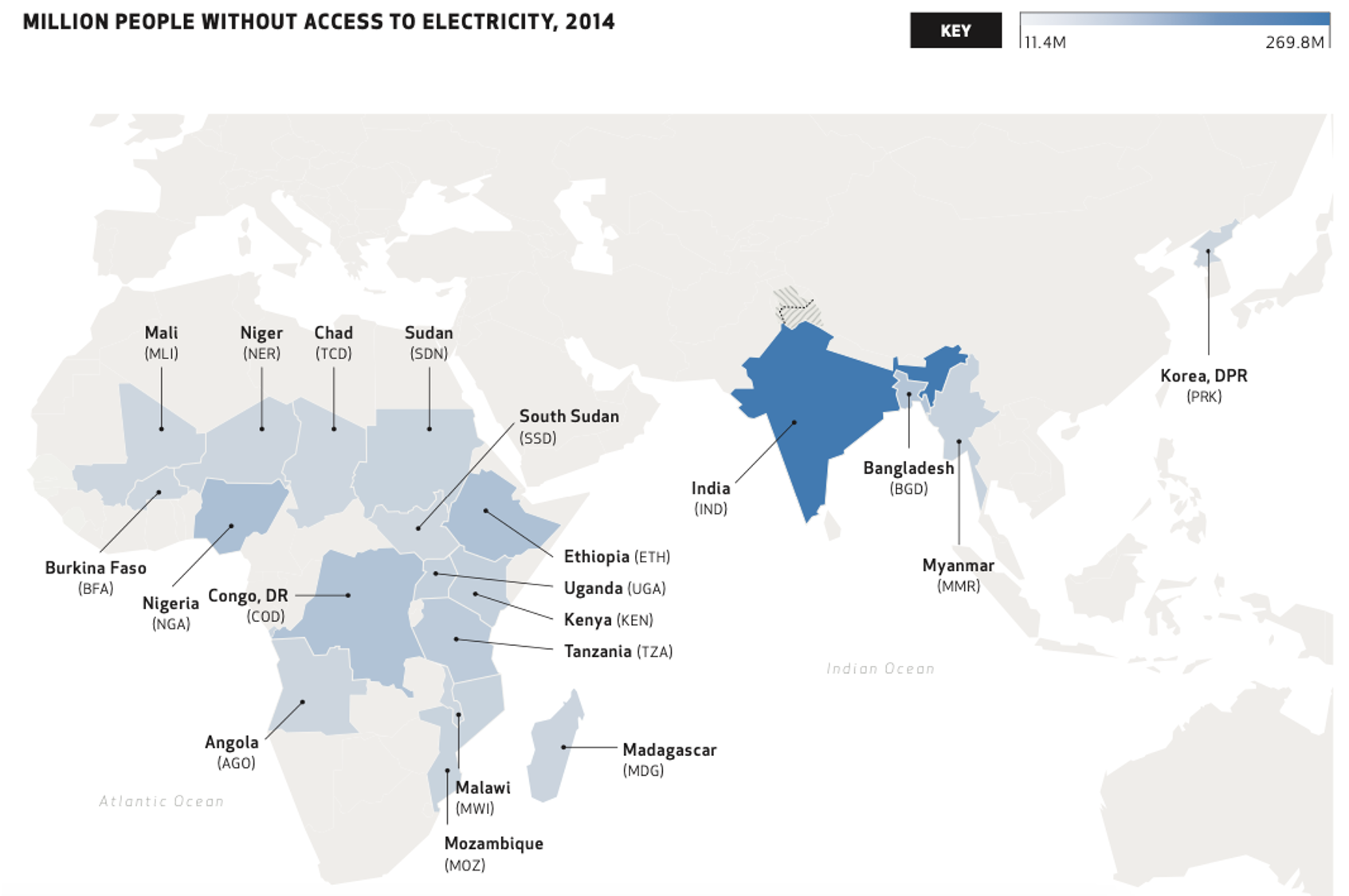
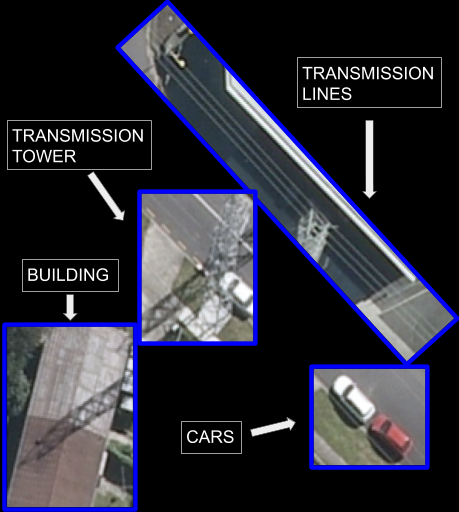
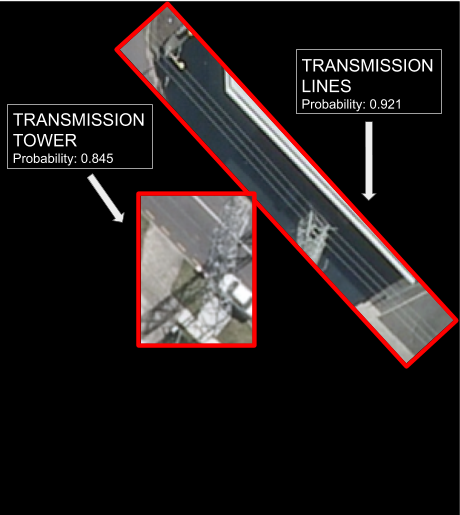
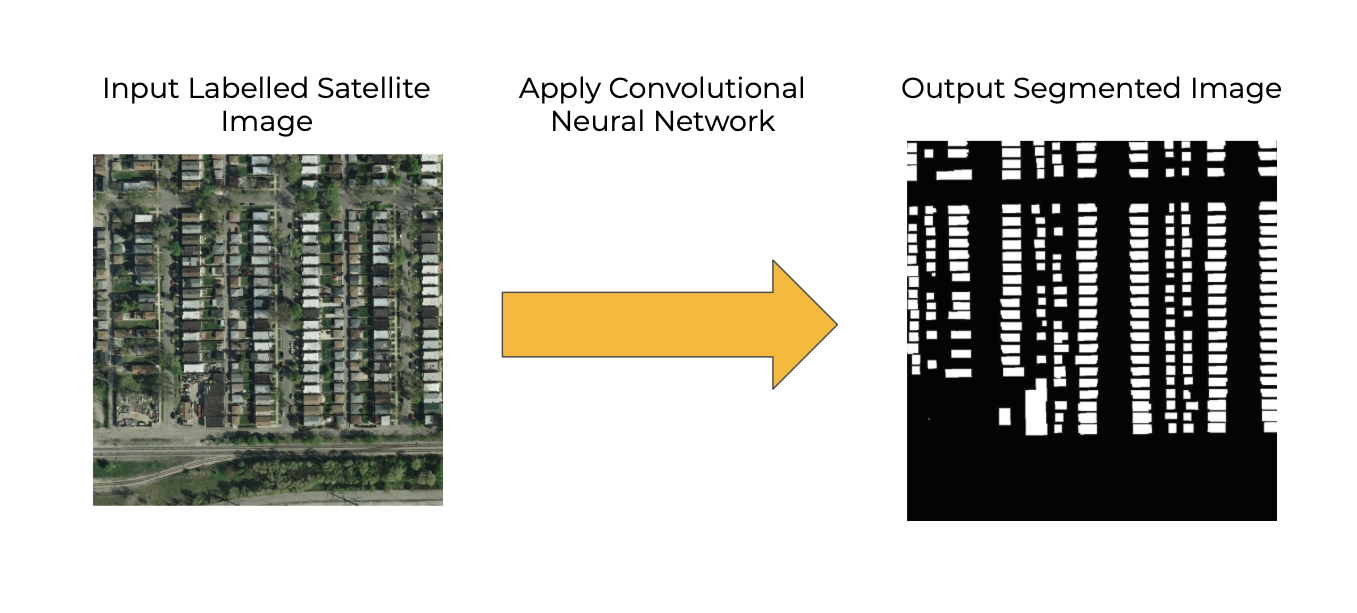
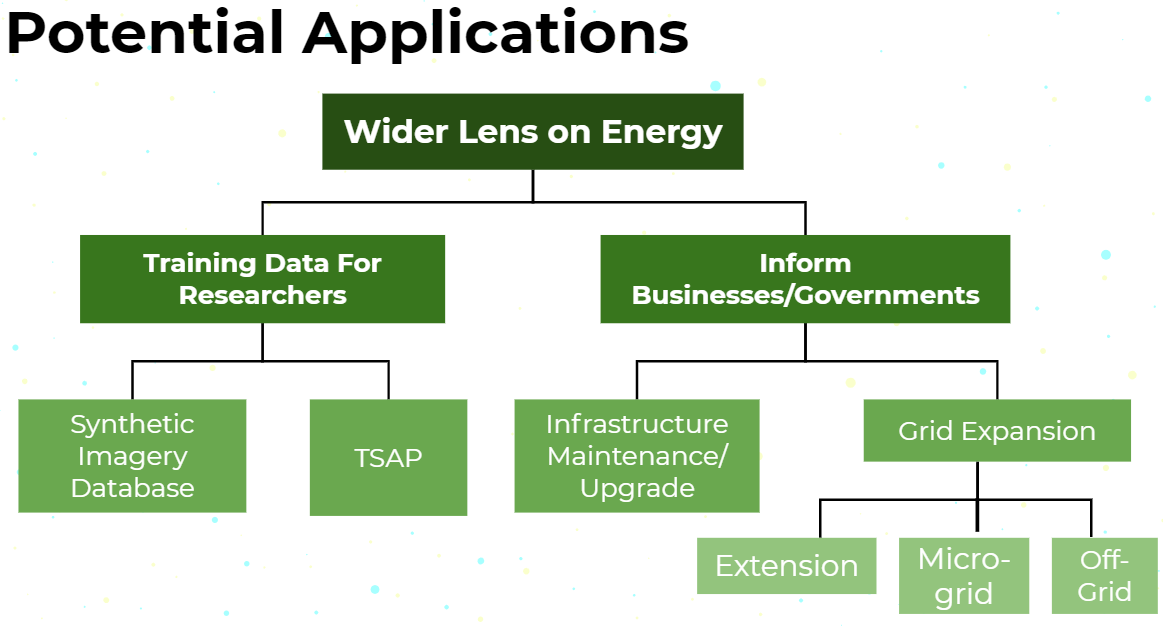
Access to electricity is one of the most important requisites to economic and societal development. It is associated with decreased maternal mortality, increased education levels, and decreased poverty. [P. Alstone, et al. Decentralized energy systems for clean electricity access. ] However, 1 billion people still lack access to electricity. To enable electrification and grid expansion in energy-poor regions, it is crucial to know where the existing infrastructure is. This information can help policymakers and businesses decide on whether to expand the national grid, build a microgrid, or provide direct off-grid solar PV. Current approaches to identifying and mapping energy infrastructure tend to be expensive and time-intensive, consisting of aggregating survey data from the ground level and roughly scaling it across regions. This is where we want to help.